Run agents against your tasksets, analyze the results, and train models on successful traces.Documentation Index
Fetch the complete documentation index at: https://docs.hud.ai/llms.txt
Use this file to discover all available pages before exploring further.
Running Evaluations
Open your taskset on hud.ai/evalsets, click Run Taskset, and configure your run: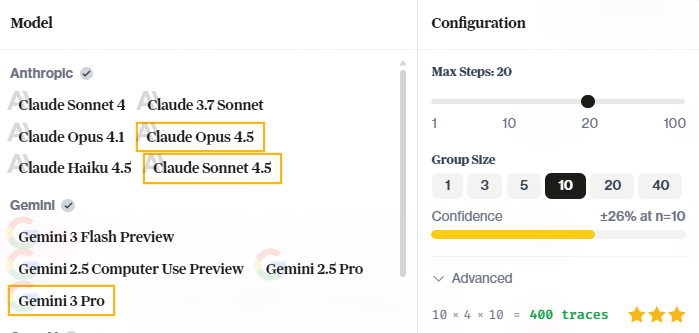
- Models — Select one or more models to evaluate. Multi-select runs the same tasks across all selected models.
- Group Size — How many times to run each task per model (more runs = higher confidence)
- Max Steps — Limit agent actions per task
Training Models
Training turns your evaluation traces into better models:- Go to hud.ai/models and find a trainable base model in Explore
- Click Fork to create your copy—this gives you your model ID
- Click Train Model and select a taskset as training data
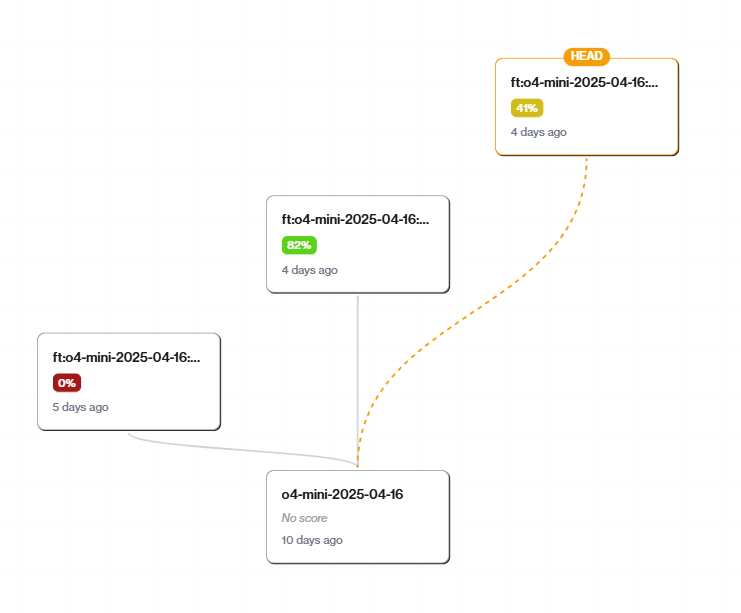
- Training creates a new checkpoint in your model’s tree
CLI Alternative
Prefer the command line? Usehud eval for running evaluations locally or remotely:
hud eval CLI reference for all options.
The Loop
Scenarios are the atomic skills your agent must get right. If your agent can’t reliably pass a scenario, that’s a gap to close — through prompting, fine-tuning, or tool design. Deploy your environment, create tasks, run evaluations, train on successful traces, use the trained model. Repeat. Every evaluation generates traces. Every training run creates a better model. Agents get better at your environment, your tasks, your success criteria.What’s Next
Platform Models
Model training and checkpoints
Platform Tasksets
Full taskset management guide
Publishing Leaderboards
Make your benchmarks public
Environments as Data
Design for useful training signal